Disclaimer: This document outlines an opinionated framework based on real-world experience. It is not a comprehensive compliance guide or a one-size-fits-all solution. Every healthcare application has unique regulatory and technical requirements. You are responsible for ensuring your own compliance with all applicable laws, including HIPAA. This guide is for educational and illustrative purposes only. Always consult with your own qualified legal and medical experts before implementing any solution in a clinical environment.
This is a Book About Plumbing
This isn’t another book about the “magic” of AI.
I’m not going to show you a new model architecture or a clever prompt that scrapes a state-of-the-art benchmark. This is a book about the plumbing. And in healthcare, the plumbing is rusty, leaky, and one burst pipe can flood the entire hospital (legally speaking).
I’ve seen projects go off the rails by chasing complexity. One common pattern is architecting a 500-user internal app on a multi-node Kubernetes cluster with huge RAG pipelines—a solution that’s operationally fragile, expensive, and fundamentally unmaintainable for the team left to support it.
This is a different path. It’s built on the simple idea that maintainability must come first.
My thesis is simple: for mission-critical apps, success isn’t the model’s intelligence. Success is the trust you can build into the system. Can you prove why the model made a decision?
If you can’t, you don’t have a product; you have a potential compliance catastrophe.
This is my framework. We’ll build a “boring” system that is practical and compliant using a hybrid stack: blending open-source (PostgreSQL, FastAPI, Docker) with simple, managed services (AWS Fargate, Amazon Bedrock) to build the most sensible solution, not the most complex one.
It All Starts With One Bad Meeting
Your journey has to start with strategy, not code. A technical success on the wrong problem is just a very expensive business failure.
The “AI Doctor” Fantasy (And How to Move Past It)
The success or failure of almost every ML system I’ve seen comes down to one thing: scoping. This is the first conversation you must have, and you must win it.
Your first job is to aggressively reject the “AI Doctor” strategy.
This is the all-too-common attempt to “replace” a clinician’s core diagnostic capabilities. I’ve seen teams burn millions on “AI Dermatology” apps—the kind that asks you to take a picture of a mole to see if it’s cancer.
It was a technical marvel that was 95% accurate in testing. It was also a complete failure when proposed for real-world use.
Why? It’s a high-risk diagnostic tool, which means years of FDA approvals. And every doctor we showed it to asked the same question: “What if it tells a patient they’re fine, but it’s a real melanoma? Who is responsible for that?” Good question.
We will not build a system that makes a final diagnosis.
Instead, our strategy targets the true source of cost and burnout: the back-office. Doctors and nurses are drowning in a sea of manual, repetitive, administrative tasks. This is the problem we will solve.
We’re not just trying to make doctors’ lives a bit easier. We’re trying to solve a catastrophic financial drain. Anyone who has spent time in a hospital ward sees it: brilliant clinicians are drowning in administrative quicksand. They spend more time clicking boxes in an EHR and fighting with paperwork than they do with patients. This administrative bloat isn’t just an inconvenience; it’s a primary driver of burnout and a source of waste.
This is the fire we’re actually trying to put out. Our “AI Intern” isn’t a cool tech demo; it’s a direct assault on the single biggest source of waste and burnout in the entire system. When you frame it this way, your project stops being a “cost center” and starts being a “revenue and retention” strategy.
Our goal is to build an “AI Intern,” not an “AI Architect.” We will augment our most expensive assets (clinicians), not try to replace them. (Bonus: an AI intern doesn’t show up late or drink all the coffee).

Here’s our mission:
“Build an AI to summarize a doctor’s messy, free-text clinical notes into suggested billing codes for a human coder to review and approve.”
This is a low-risk, high-ROI tool that solves a concrete administrative problem.
So, you get them to agree on a 1-pager. This is your “contract.” It’s your shield against the inevitable scope creep. It should look something like this:
1-Page Project Scoping Document: AI Billing Code Suggester
| Field | Description |
| The Target Process: | Manually reading 10-page clinical notes to find 3-5 billing codes. |
| The “AI Intern” Persona: | “Billing Code Intern.” |
| The “AI Intern’s” Task: | It reads a doctor’s free-text note and suggests 3-5 billing codes, with citations, for a human to review. |
| ML Problem Framing: | RAG-based Classification. The system retrieves similar notes and code definitions, then an LLM classifies the note based on that context. |
| The Human-in-the-Loop: | A certified Senior Billing Coder. |
| Core Metric (KPI): | “Clinical-Hours Reclaimed” (e.g., Reduce manual review time per note from 15 mins to 2 mins). |
| Out of Scope: | We are NOT building an ‘AI Doctor.’ The AI will NOT make a final billing decision. It will NOT diagnose patients. |
The “Napkin” Risk Model You Show to Your Boss
Before you write a single line of code, you must present this simple risk model to your stakeholders. This is what justifies your “boring” architecture.
The “Mitigation” column in the table below outlines the core layers of that architecture. Don’t worry, I will explain exactly what these components—like ‘RAG’, ‘Ingress Filter’, and ‘Governance Stack’—are in detail in the next section.
| Risk | Likelihood | Severity | Mitigation (Our Architecture) |
| Model Hallucination (PHI Leak) | Low | Catastrophic | Layer 3 (Egress Filter): Scan all output for PII patterns. RAG Architecture: Limits context to a single patient, reducing “gossip” risk. |
| Incorrect Billing Code | Medium | Medium | HITL Workflow: 100% of suggestions are reviewed by a human expert. The AI suggests, it never decides. |
| Data “Gossip” (Access Violation) | Low | Catastrophic | Layer 2 (Governance): patient_id check is performed before the vector search. The AI cannot read data it’s not permissioned for. |
| Concept Drift (e.g., COVID) | High | High | Monitoring (Day 2): Track HITL Rejection Rate. A spike means the model is wrong. Retraining Pipeline: Use the HITL data to constantly update the model. |
| Bad Prompt (Injection Attack) | Medium | High | Layer 1 (Ingress Filter): Sanitize all user input for keywords like “ignore instructions”. |
This matrix is your best defense. You are showing that you are not building for the best case; you are building to survive the worst case.
Data Isn’t “Big,” It’s “Toxic”
With our strategy set, we build the foundation. No model can fix bad data.
In high-compliance fields, data isn’t just “big”; it’s “toxic.” A single unprotected row of PHI can lead to a huge HIPAA fine.
The most dangerous misconception is the “myth of anonymization.” Stripping the 18 HIPAA-specified identifiers (name, SSN) is not enough. Individuals can be re-identified with high accuracy using just a few “anonymous” data points (e.g., zip code, date of birth, and gender).
Therefore, our architecture must be built on a foundation of explicit, verifiable governance.
This brings us to the first real architectural decision you’ll make: RAG or Fine-Tuning.
This isn’t a theoretical debate; it’s a fundamental compliance and security architecture decision. And we learned this the hard way.
When you Fine-Tune a model, you’re essentially “baking” your sensitive PHI directly into the model’s brain. It memorizes this data. This creates a black box with irreversible risks. We’ve seen it happen. You can’t just run a DELETE query on a model’s weights to remove Patient X’s data. And when you face a compliance review, you’re in a terrible position: you can’t prove why it made a bad decision, and you can’t hand over the model because it’s contaminated with all your other patients’ PHI.
RAG (Retrieval-Augmented Generation) is the exact opposite, and it’s our entire compliance strategy.
Standard LLMs have two massive limitations:
- Their knowledge is “frozen in time” to their last training date, and
- They have zero knowledge of your private, domain-specific data (like Patient X’s chart). Ask them about Patient X, and they will either refuse or, much worse, hallucinate an answer.
RAG is the architectural pattern that solves this. It’s a two-step process:
-
Retrieval (The ‘R’): Before we ever talk to the LLM, we take the user’s prompt (e.g.,
"Summarize Patient X's recent visit") and use it to query our own secure database. This is the vector search (againstpg_vector) that finds the top 3-5 actual documents related to Patient X (e.g.,doc_1: "Note from 11/15...", doc_2: "Lab results from 11/14..."). -
Augmentation (The ‘A’): We then augment the original prompt. We build a new, much larger prompt that stuffs those retrieved documents into the context window. The final prompt we send to the LLM looks like this:
Context:
---
Document 1: "Note from 11/15: Patient presents with chest pain..."
Document 2: "Lab results from 11/14: Troponin levels normal..."
---
User Request:
"Summarize Patient X's recent visit"
The LLM then Generates (the ‘G’) an answer based only on that fresh, specific, and secure context we just provided. It’s not using its “memorized” generic brain; it’s reasoning over the exact data we gave it.
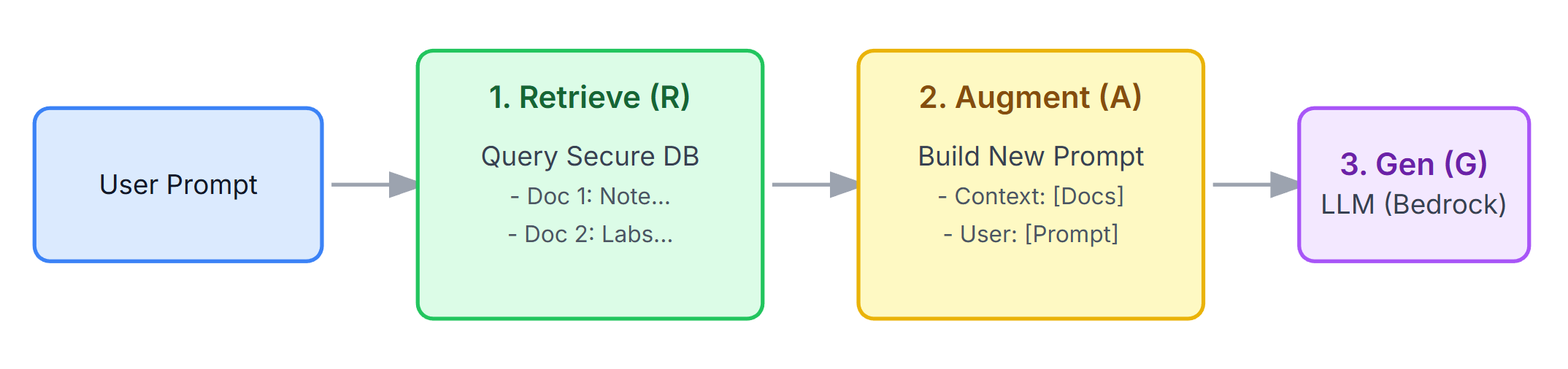 Figure 1: Our RAG “two-step” workflow. The AI (Logic) isn’t pre-trained on PHI. It (1) retrieves small, specific pieces of PHI (Knowledge) from our secure DB, and (2) uses that context to generate an answer.
Figure 1: Our RAG “two-step” workflow. The AI (Logic) isn’t pre-trained on PHI. It (1) retrieves small, specific pieces of PHI (Knowledge) from our secure DB, and (2) uses that context to generate an answer.
This separation is a profound architectural victory. It means we get:
-
Auditability: We can prove exactly which documents the AI read to make its decision. This is your “Chain of Custody” for any compliance review.
-
Access Control: We check permissions before the AI retrieves anything.
-
Data Management: To “forget” a patient, we just run a standard
DELETEquery on our database. The AI logic remains clean.

That 99% Accurate Model That Was 100% Useless
Don’t even get me started on data leakage. I once had to review a “99% accurate” model… it turned out the model wasn’t detecting pneumonia at all. It had learned that all scans from “Hospital A” (which had the severe cases) were taken with a different X-ray machine than “Hospital B” (the control group).
The model was 99% accurate at detecting the scanner’s brand, not the disease.
This is Data Leakage: when your model learns from data that it will not have at the time of prediction. It is the #1 cause of models that have 99% accuracy in testing but 50% in production.
Watch out for the common ways this bites you:
-
The most embarrassing one is when you accidentally include the answer in the question. You’re trying to predict
length_of_stayat admission, but you accidentally included the actuallength_of_stayas a feature. Your model is 100% accurate because it’s cheating. (Yes, this really happens). -
Another common one is messing up your data prep order. You normalize your data, so you find the mean and max of the entire dataset before splitting it into train and test sets. This is a mistake. Information from the test set has “leaked” into the train set. The cardinal rule: Always split your data first.
-
But the most insidious one is when you forget who the data belongs to. You have 10 scans from Patient A. You randomly split them, 5 in train and 5 in test. Your model learns to recognize Patient A’s unique physiology, not cancer. It will fail on Patient B. The solution: Always split by
patient_id, not byscan_id.
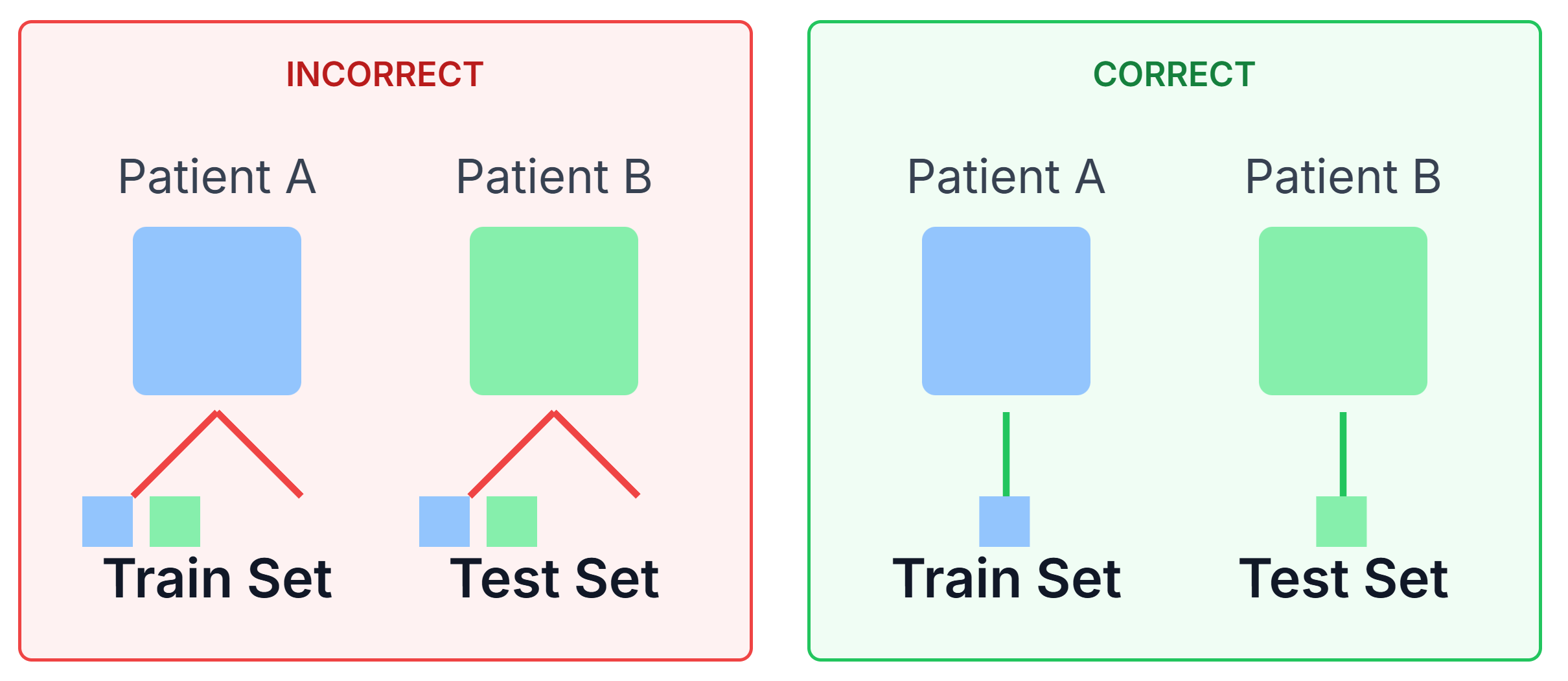
Figure 2: A diagram illustrating the “Group Leak.” On the left (Incorrect), scans from Patient A are in both Train and Test. On the right (Correct), all scans for Patient A are in the Train set, and all scans for Patient B are in the Test set.
Building the “Boring” (and Bulletproof) Sandbox
So, how do you build this? You build a ‘sandbox.’ You assume the AI is a brilliant, probabilistic, and completely untrustworthy intern, and you put four layers of deterministic rules around it.
This is our 4-Layer “Compliance Stack”:
-
Layer 1: The Ingress Gateway (The “Guard”): Intercepts 100% of user prompts. This is where we implement PHI Masking (e.g., with regex) and Prompt Sanitization to solve prompt injection.
-
Layer 2: The Governance Stack (The “Librarian”): Controls what knowledge the AI is allowed to “read.” This is where we implement ABAC-on-Retrieval. The RAG retriever is integrated with the user’s session and runs an ABAC check before the vector search.
-
Layer 3: The Egress Gateway (The “Lawyer”): Intercepts 100% of the AI’s raw answer. This is our last line of defense. We run PHI Filtering (scanning for “gossiped” PII) and Deterministic Guardrails (e.g.,
IF response.drug_dosage_mg > 500 THEN block_and_alert). -
Layer 4: The Verifiability Stack (The “Security Camera”): An immutable, append-only log for every transaction. This is our “Proof of History.” We log the raw prompt, the sanitized prompt, the doc IDs retrieved, the raw AI response, and the final filtered response.
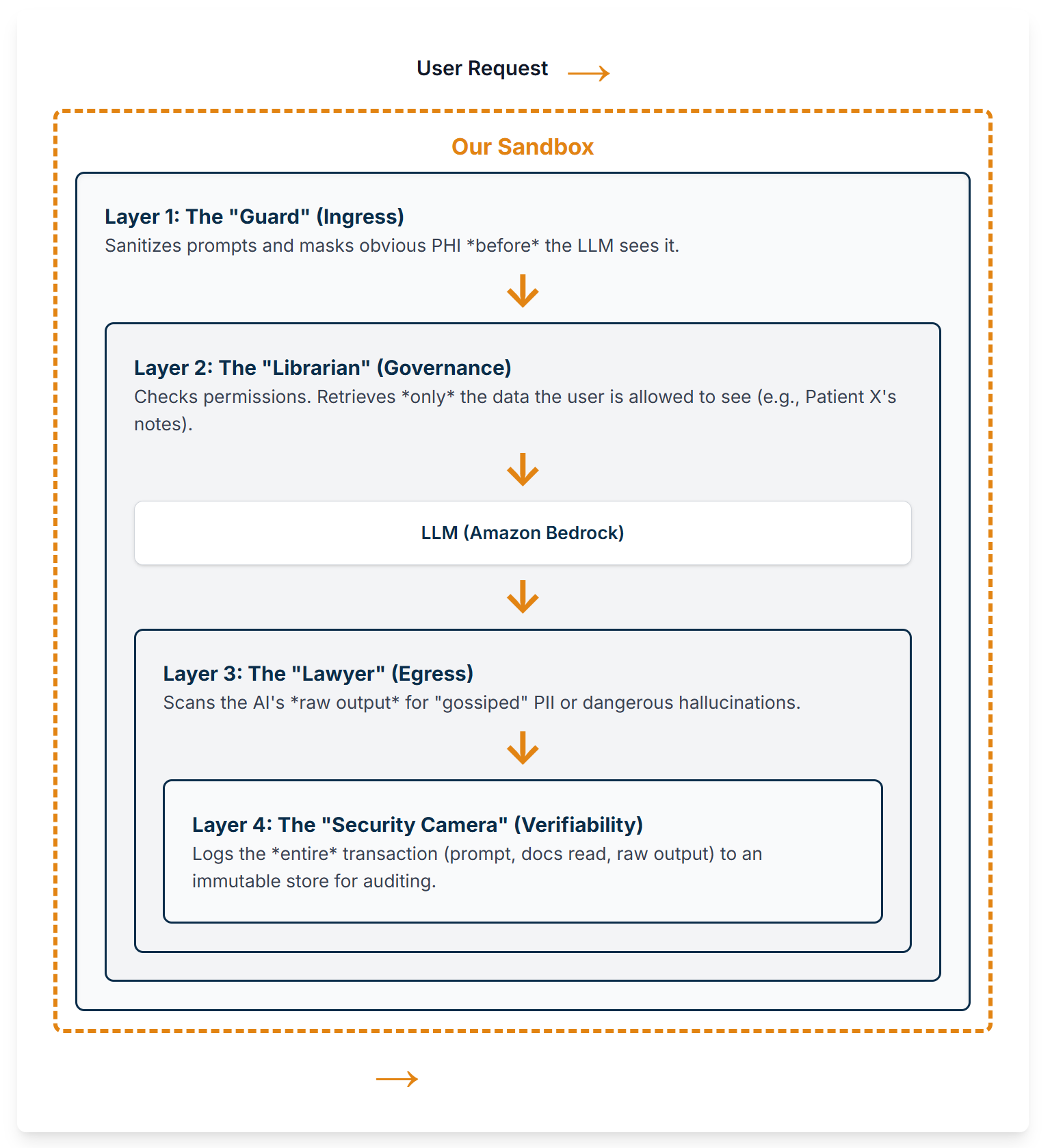
Figure 3: The 4-Layer Compliance Sandbox. A user’s request passes through Ingress (L1) and Governance (L2) before reaching the LLM, and its response is filtered by Egress (L3). The entire process is logged by Verifiability (L4).
Our Stack: The Maintainable “Monolith”
People will try to sell you on Kubernetes, Kafka, and three different vector databases. Don’t listen to them. Your 500-user app doesn’t need FAANG-level infrastructure. It needs to not break.
Here’s our stack. It’s boring. That’s why it works.
-
Application (The “Monolith”): Docker + FastAPI. It’s fast, standard, and portable.
-
Application Hosting: AWS Fargate. Why? Because I don’t want to be on-call for a K8s control plane, and you probably don’t either.
-
Database (RAG, HITL, Logs): Amazon RDS for PostgreSQL + pg_vector. This is the key. We consolidate our relational, document, and vector data into one database we already know how to manage. This is a massive win.
-
A Quick Detour: Why pg_vector is a Huge Compliance Win
-
Using a separate vector database (like Pinecone, Weaviate, etc.) is a popular technical choice. In healthcare, it’s often a compliance mistake.
-
Why? Because now you have two databases holding PHI that you must secure, audit, and manage. How do you guarantee that when a patient’s record is deleted from your primary Postgres DB, it’s also instantly and verifiably deleted from the vector DB? It’s a nightmare of synchronization and potential data spillage.
-
By keeping the vectors in the same Postgres database as the source data (
patient_notestable), you get a massive win. A singleDELETE FROM patient_notes WHERE patient_id=123wipes out the note and its vector. Your data management is atomic, simple, and defensible. -
LLM Model (The “Logic”): Amazon Bedrock. Calling a managed, HIPAA-eligible API is infinitely simpler and more secure than self-hosting.
-
Logging (Layer 4): Amazon CloudWatch. It’s native to Fargate. The app just
print()s JSON, and CloudWatch handles the rest.
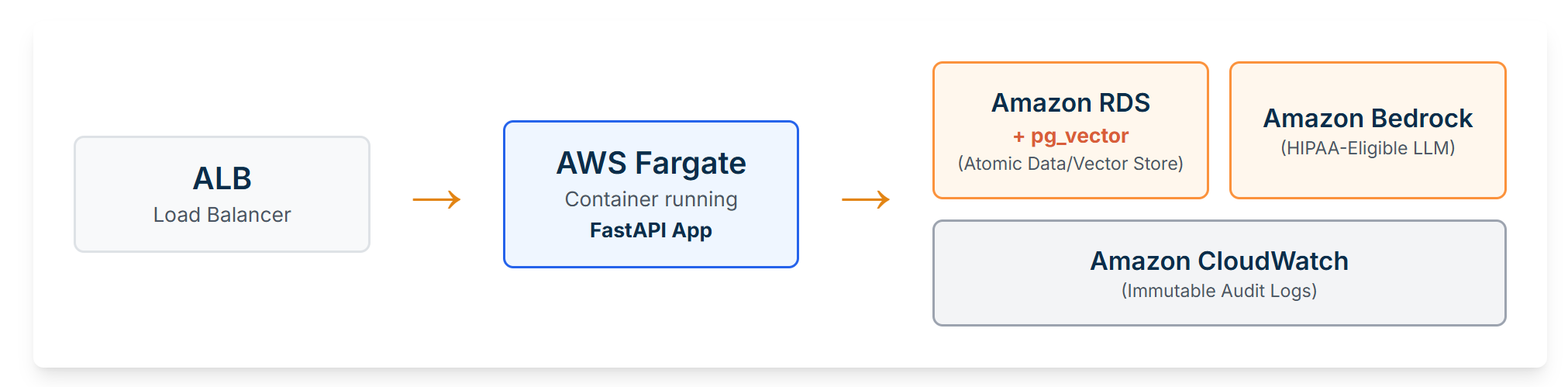
Figure 4: Our pragmatic reference architecture. An ALB routes traffic to a Fargate container. The container executes logic by querying Amazon RDS (for data/vectors) and Amazon Bedrock (for LLM logic). All logs are captured by Amazon CloudWatch.
The Code: The Asynchronous Shuffle
This all comes together with one key insight: you must be asynchronous.
A synchronous “chatbot” is the most dangerous pattern in healthcare. A single hallucination goes straight to the user.
Our architecture does the “asynchronous shuffle.” The API (1) takes the request, (2) immediately returns a 202 Accepted (like ‘Got it, I’m on it!’), and (3) shoves the task into a database queue.
This means you need a second app: the “Review Dashboard” for the human expert. This is where the real work happens. That dashboard simply runs SELECT * FROM review_queue WHERE status = 'pending_review'.
The UI for this is critical.
-
Poor UI: A text box with the AI’s full summary.
-
Good UI: “AI suggests adding these 3 billing codes: [99213, 99214, 99203].” The UI highlights only the additions. The user has two simple buttons: [Approve] [Reject].
Those two buttons [Approve] [Reject] they are the final, critical piece. They are the most expensive, high-quality data-labeling machine you will ever build.
Implementing the “Other Half”: The Review Dashboard
Don’t overthink this. This is the “back-office” for your “back-office AI.” It’s just a simple, internal CRUD (Create, Read, Update, Delete) application.
-
Stack: Build it in whatever your team knows. A simple React or Vue.js frontend, or even a Python-based tool like Streamlit or Dash.
-
Hosting: Host it as another “boring” Fargate service. It has one job:
SELECTfrom thereview_queuetable andUPDATEthestatusfield when a human clicks a button. -
Key Feature: The only critical feature is a good “diff” view that clearly highlights what the AI is suggesting, to minimize the human’s cognitive load.
Here’s the database schema that makes this all possible. (Yes, it’s just three tables in one Postgres DB).
-- Enable the vector extension
CREATE EXTENSION IF NOT EXISTS vector;
-- 1. Our RAG "Knowledge" Library (for Layer 2)
CREATE TABLE patient_notes (
note_id UUID PRIMARY KEY,
patient_id VARCHAR(100) NOT NULL,
doctor_id VARCHAR(100) NOT NULL,
note_content TEXT,
embedding vector(1024) -- 1024 for Bedrock's Cohere embeddings
);
-- Create an index for fast vector search
CREATE INDEX ON patient_notes USING HNSW (embedding vector_l2_ops);
-- 2. The HITL "Review Queue" (This is the core of the app)
CREATE TABLE review_queue (
task_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
user_id VARCHAR(100) NOT NULL,
raw_prompt TEXT,
final_ai_response TEXT,
suggested_billing_codes JSONB, -- e.g., {"codes": ["99213", "99214"]}
status VARCHAR(50) DEFAULT 'pending_review', -- pending_review, approved, rejected
created_at TIMESTAMPTZ DEFAULT now(), -- Fixed the typo. You're welcome.
reviewed_by VARCHAR(100),
reviewed_at TIMESTAMPTZ
);
-- 3. The Layer 4 "Verifiability" Log (The "Security Camera")
CREATE TABLE transaction_log (
log_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
timestamp TIMESTAMPTZ DEFAULT now(),
user_id VARCHAR(100),
full_transaction JSONB -- A single JSON blob with the whole story
);
 Figure 5: The Asynchronous HITL workflow. The API (1) immediately returns a
Figure 5: The Asynchronous HITL workflow. The API (1) immediately returns a 202 Accepted to the user and (2) places the task in the review_queue. A human expert (3) reviews this queue on a separate dashboard, creating a safe feedback loop.
Practical Example: API Request/Response JSON
Here is the actual flow in practice. A doctor’s workstation sends this:
Request (POST /api/v1/summarize_notes):
{
"user_id": "dr.smith",
"patient_id": "PID-12345",
"raw_prompt": "Patient presents with chest pain and shortness of breath. History of HTN. EKG normal. Suspect GERD. - J. Smith MD"
}
The server immediately responds with this, while the AI job runs in the background:
Response (202Accepted`):
{
"status": "pending_review",
"task_id": "a1b2c3d4-e5f6-7890-1234-567890abcdef"
}
The frontend can now just poll for this task_id or wait for a websocket push.
And here’s the FastAPI code that implements this flow.
# --- main_app.py (The Orchestrator) ---
from fastapi import FastAPI, HTTPException, BackgroundTasks, Request
from pydantic import BaseModel
import aioboto3 # Async boto3
import asyncpg # Async PostgreSQL driver
import json
import logging
import uuid
import re
import os
from datetime import datetime
from contextlib import asynccontextmanager
# --- Configuration ---
DATABASE_URL = os.environ.get("DATABASE_URL", "postgresql://user:password@localhost/health_db")
BEDROCK_REGION = os.environ.get("BEDROCK_REGION", "us-east-1")
BEDROCK_EMBEDDING_MODEL = os.environ.get("BEDROCK_EMBEDDING_MODEL", "cohere.embed-english-v3")
BEDROCK_LLM_MODEL = os.environ.get("BEDROCK_LLM_MODEL", "anthropic.claude-3-sonnet-20240229-v1:0")
# --- Global clients (managed by lifespan) ---
# We use a dictionary to store clients that will be initialized at startup
app_state = {}
@asynccontextmanager
async def lifespan(app: FastAPI):
# --- Startup ---
# Create asyncpg connection pool
app_state["db_pool"] = await asyncpg.create_pool(
dsn=DATABASE_URL,
min_size=1,
max_size=10
)
# Create aioboto3 session and client
session = aioboto3.Session()
app_state["bedrock_client"] = session.client('bedrock-runtime', region_name=BEDROCK_REGION)
logger.info("Application startup: DB pool and Bedrock client created.")
yield
# --- Shutdown ---
await app_state["db_pool"].close()
# aioboto3 clients are managed by the session, which cleans up automatically
logger.info("Application shutdown: DB pool closed.")
# --- FastAPI App ---
app = FastAPI(lifespan=lifespan)
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(message)s')
logger = logging.getLogger('VerifiabilityLogger')
class SummarizeRequest(BaseModel):
user_id: str
patient_id: str
raw_prompt: str
# --- Layer 1: Ingress (Real Implementation) ---
def l1_ingress_gateway(raw_prompt: str) -> (str, dict):
"""Layer 1: Cleans and masks a raw user prompt."""
# Simple example: mask SSNs. A real implementation would be more robust.
sanitized_prompt, count = re.subn(
r'\b\d{3}-\d{2}-\d{4}\b', '[SSN_MASKED]', raw_prompt
)
masked_info = {"ssn_masked_count": count}
# Add more regex for names, DOBs, etc. as needed
return sanitized_prompt, masked_info
# --- Layer 3: Egress (Real Implementation) ---
def l3_egress_gateway(raw_llm_response: str) -> str:
"""Layer 3: Scans the AI's raw output for leaks or dangerous 'hallucinations.'"""
# 1. Check for "hallucinated" PII (e.g., credit card numbers)
if re.search(r'\b\d{4}-\d{4}-\d{4}-\d{4}\b', raw_llm_response):
raise ValueError("Response contains a potential credit card leak.")
# 2. Check Deterministic Guardrails
if "i am not a doctor" not in raw_llm_response.lower():
raw_llm_response += "\n\n(This is an AI-generated summary and not medical advice.)"
return raw_llm_response
# --- Database & Bedrock Helper Functions (Real Async) ---
async def get_embedding(text: str, client):
"""Generates an embedding for a given text using Bedrock."""
body = json.dumps({"texts": [text], "input_type": "search_document"})
try:
response = await client.invoke_model(
body=body,
modelId=BEDROCK_EMBEDDING_MODEL,
contentType='application/json',
accept='application/json'
)
response_body = json.loads(await response['body'].read())
return response_body['embeddings'][0]
except Exception as e:
logger.error(f"Bedrock embedding call failed: {e}")
raise
async def check_user_patient_access(pool, user_id: str, patient_id: str) -> bool:
"""(L2) Checks if a user has access to a patient. (Mocked logic, real query)"""
# This query is hypothetical. You *must* replace this with your real
# authorization logic against your user/permissions tables.
query = "SELECT 1 FROM user_permissions WHERE user_id = $1 AND patient_id = $2 LIMIT 1"
# For this demo, we'll just return True, but in production, you'd run the query.
# result = await pool.fetchrow(query, user_id, patient_id)
# return result is not None
return True # Mocking the *result* but showing the *query*
async def query_vector_db(pool, patient_id: str, embedding: list, limit: int = 5):
"""(L2) Performs a vector search *scoped* to a single patient."""
# <-> is the L2 distance operator from pg_vector
query = """
SELECT note_id, note_content
FROM patient_notes
WHERE patient_id = $1
ORDER BY embedding <=> $2
LIMIT $3
"""
try:
rows = await pool.fetch(query, patient_id, embedding, limit)
return [{"note_id": str(row['note_id']), "note_content": row['note_content']} for row in rows]
except Exception as e:
logger.error(f"Vector DB query failed: {e}")
return []
async def create_review_task(pool, user_id, raw_prompt, final_ai_response, suggested_billing_codes):
"""Saves the AI suggestion to the HITL review queue."""
query = """
INSERT INTO review_queue (user_id, raw_prompt, final_ai_response, suggested_billing_codes, status)
VALUES ($1, $2, $3, $4, 'pending_review')
RETURNING task_id
"""
try:
task_id = await pool.fetchval(query, user_id, raw_prompt, final_ai_response, json.dumps(suggested_billing_codes))
return task_id
except Exception as e:
logger.error(f"Failed to create review task: {e}")
raise
# --- Main API Endpoint ---
@app.post("/api/v1/summarize_notes")
async def summarize_notes(request: SummarizeRequest, background_tasks: BackgroundTasks):
"""The full, orchestrated flow for a safe, auditable AI request."""
# Get clients from application state
db_pool = app_state["db_pool"]
bedrock_client = app_state["bedrock_client"]
# This transaction object is our Layer 4 log
transaction = {
"log_id": str(uuid.uuid4()),
"timestamp": datetime.utcnow().isoformat(),
"user_id": request.user_id,
"patient_id": request.patient_id,
"raw_prompt": request.raw_prompt,
"status": "processing",
"error": None
}
try:
# === LAYER 1: INGRESS ===
sanitized_prompt, masked = l1_ingress_gateway(request.raw_prompt)
transaction["l1_sanitized_prompt"] = sanitized_prompt
transaction["l1_masked_info"] = masked
# === LAYER 2: GOVERNANCE ===
if not await check_user_patient_access(db_pool, request.user_id, request.patient_id):
raise PermissionError(f"User {request.user_id} cannot access Patient {request.patient_id}")
prompt_embedding = await get_embedding(sanitized_prompt, bedrock_client)
retrieved_docs = await query_vector_db(
db_pool, request.patient_id, prompt_embedding, limit=5
)
doc_ids = [doc['note_id'] for doc in retrieved_docs]
context = " ".join([doc['note_content'] for doc in retrieved_docs])
transaction["l2_retrieved_doc_ids"] = doc_ids
# === LLM CALL (The "Magic" Bit - Real Call) ===
final_llm_prompt = f"System: You are a helpful clinical assistant. Using *only* the following context, extract the suggested ICD-10 and CPT billing codes. Return *only* a valid JSON object with a single key 'codes', which is an array of strings. Do not include any other text or apologies.\n\nContext:\n{context}\n\nUser Request:\n{sanitized_prompt}"
body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1024,
"messages": [{"role": "user", "content": final_llm_prompt}]
})
response = await bedrock_client.invoke_model(
body=body, modelId=BEDROCK_LLM_MODEL
)
response_body = json.loads(await response['body'].read())
raw_llm_response = response_body['content'][0]['text']
transaction["l3_raw_llm_response"] = raw_llm_response
# === LAYER 3: EGRESS ===
final_response = l3_egress_gateway(raw_llm_response)
transaction["l3_final_response"] = final_response
# Try to parse the codes from the raw response
try:
suggested_billing_codes = json.loads(raw_llm_response)
except json.JSONDecodeError:
logger.warn(f"LLM response was not valid JSON: {raw_llm_response}")
suggested_billing_codes = {"codes": []} # Fallback
# === HITL QUEUE (The "Shuffle") ===
task_id = await create_review_task(
db_pool,
user_id=request.user_id,
raw_prompt=request.raw_prompt,
final_ai_response=final_response,
suggested_billing_codes=suggested_billing_codes
)
transaction["hitl_task_id"] = str(task_id)
transaction["status"] = "pending_review"
# === FINAL RESPONSE TO USER (The "Got it!") ===
response_to_user = {"status": "pending_review", "task_id": str(task_id)}
# === LAYER 4: VERIFIABILITY ===
background_tasks.add_task(logger.info, json.dumps(transaction))
return response_to_user
except PermissionError as e:
transaction["status"] = "failed"
transaction["error"] = f"PermissionError: {str(e)}"
logger.warn(json.dumps(transaction)) # Log auth failures
raise HTTPException(status_code=403, detail=str(e))
except Exception as e:
# Catch-all
transaction["status"] = "failed"
transaction["error"] = f"InternalError: {str(e)}"
background_tasks.add_task(logger.error, json.dumps(transaction))
raise HTTPException(status_code=500, detail="An internal error occurred.")
What Your “Proof of History” Log Actually Looks Like
When we call logger.info(json.dumps(transaction)), this is what actually gets written to CloudWatch. This JSON object is your “Proof of History” and your legal defense.
Sample Log Schema (full_transaction blob):
{
"log_id": "a1b2c3d4-e5f6-7890-1234-567890abcdef",
"timestamp": "2025-11-16T00:30:15.123Z",
"user_id": "dr.smith",
"patient_id": "PID-12345",
"raw_prompt": "Patient presents with chest pain and shortness of breath. History of HTN. EKG normal. Suspect GERD. - J. Smith MD",
"status": "pending_review",
"error": null,
"l1_sanitized_prompt": "Patient presents with chest pain and shortness of breath. History of HTN. EKG normal. Suspect GERD. - J. Smith MD",
"l1_masked_info": {
"ssn_masked_count": 0,
"dob_masked_count": 0
},
"l2_retrieved_doc_ids": [
"doc-uuid-1",
"doc-uuid-2",
"doc-uuid-3"
],
"l3_raw_llm_response": "{\"codes\": [\"R07.9\", \"R06.02\", \"I10\"]}",
"l3_final_response": "{\"codes\": [\"R07.9\", \"R06.02\", \"I10\"]}\n\n(This is an AI-generated summary and not medical advice.)",
"hitl_task_id": "f4g5h6j7-k8l9-1234-5678-m9n0o1p2q3r4"
}
The “Go-Live” Compliance Checklist
Before you let a single real user touch this, you must be able to check “YES” on all of these.
-
(L4) Audit Logging: Is every single API request (including the exact documents retrieved by RAG) logged to an immutable store?
-
(L2) Access Control: Is your RAG query provably filtered by
patient_idor an equivalent access token before the vector search?. -
(L1) Data Minimization (Ingress): Are you masking obvious PHI before it ever hits the LLM?
-
(L3) Egress Filtering: Are you scanning the LLM’s raw output for “gossiped” PII or hallucinations before it’s saved or shown to a user?
-
(Data) Data Lifecycle: Is your pg_vector data deleted atomically with its source row?.
-
(HITL) Human Mandate: Is there a mandatory human gate (the
review_queue) before any high-risk decision (like billing or diagnosis) is finalized? -
(Ops) Safety Switch: Can you disable the entire AI feature set (and fallback to 100% manual) in < 1 minute without a code deployment?
The “Day 2” Problem (Or: Why It’s All On Fire)
You built it. It works. You celebrate. The project is “shipped.” You’re wrong. The real work starts now. This is the “Day 2” problem, and it’s where everything catches fire.
Your model’s performance always degrades. This is “model rot.” Data changes in the real world, and your model’s beautiful, static view of the world becomes a liability.
The “Unhappy Path”: Your Error Handling & Fallback Tree
Designing for failure is more important than designing for success. Here is our fallback structure:
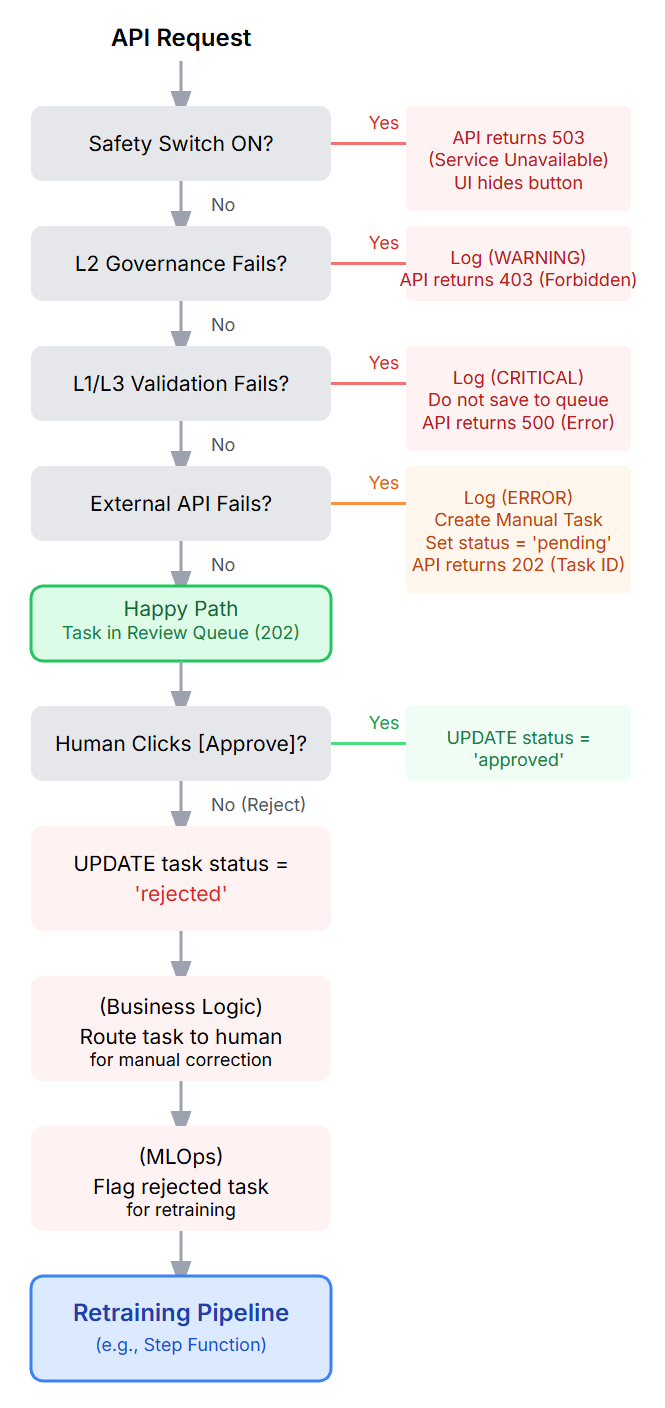
Figure 6: A flowchart visualizing the “Unhappy Path.” It shows branches for the Global Safety Switch (503), PermissionError (403), Validation Fail (500), and External API Timeout (202 with manual fallback).
Proving It’s Actually Working (And Not Just “On”)
This is the most important part of “Day 2.” Your system is running, but is it effective? Your uptime metrics are for you; these effectiveness metrics are for the business.
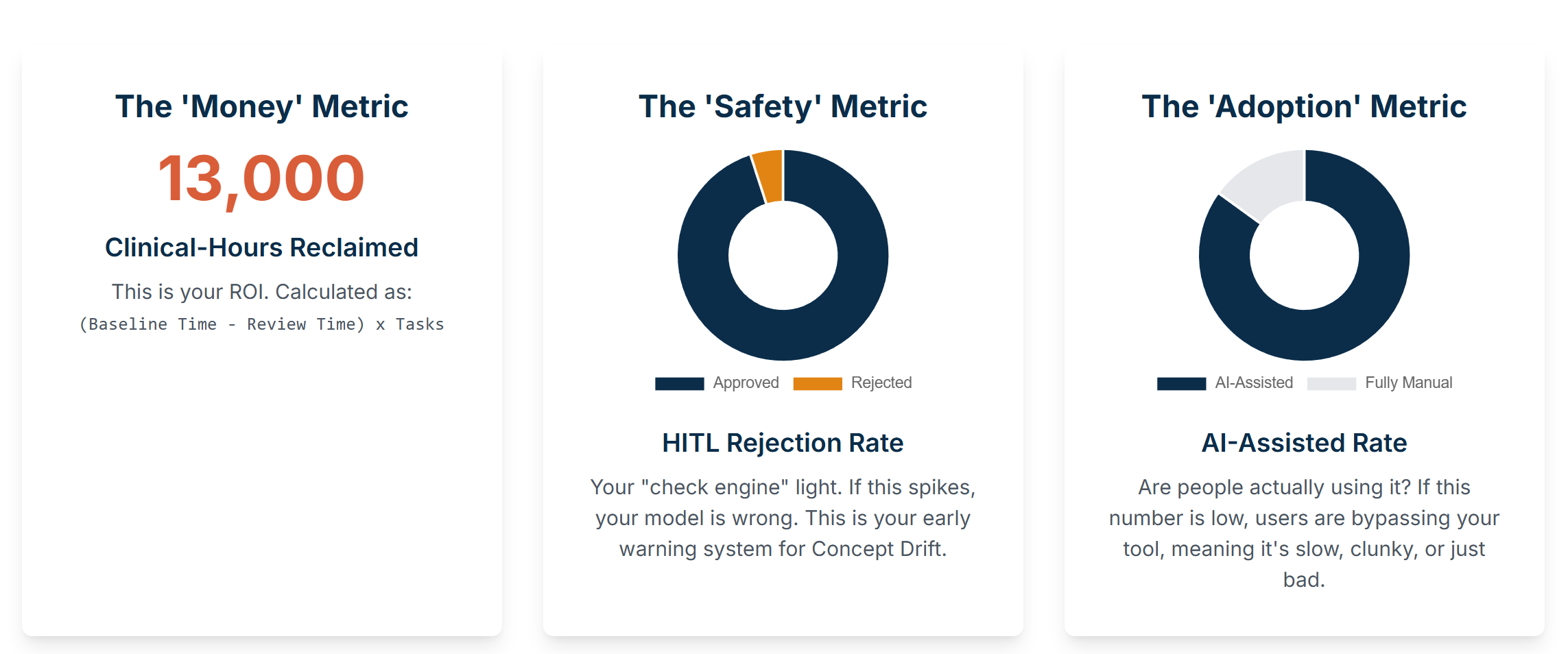
Remember that “Clinical-Hours Reclaimed” KPI we sold to the business on the 1-Pager? Now we have to prove it.
First, you’ve got to prove you’re actually saving time. This is the only number your execs will care about. Before you launch, you must get a baseline. Go sit with a coder and time them with a stopwatch if you have to. “Okay, 15 minutes per note.” Got it. Now, you have to instrument your Review Dashboard. This is non-negotiable. Add a timestamp in your database for when the task is first loaded by a human, and another for when they click [Approve] or [Reject]. The difference is your Avg_Review_Time. Your slide deck formula is simple: (15_min_baseline - 2_min_review_time) * 1000_tasks_processed = X hours reclaimed. That’s your bonus.
Next, you need to know if the model is spitting out garbage. This is your “check engine” light, and it’s the most important metric for the engineering team. It’s the HITL Rejection Rate. Just Total_Rejected / Total_Reviewed. You must put this on a dashboard that your entire team sees every day. If that rate is sitting at a healthy 5% and suddenly spikes to 15% on a Tuesday, you know immediately that your model is wrong. This is your “Concept Drift” early warning system. That COVID billing code example? This metric would have caught it in one day, not six months.
Finally, you need a sanity check to see if people hate your tool. You need to know if they’re finding ways to bypass it. I call this the AI_Assisted_Rate. You just track the Total_Tasks_Processed_via_HITL against the Total_Notes_Coded in the entire billing system. If this number is low, it means your users are actively avoiding your system. They’re ignoring the review queue and just doing it the old manual way. This is a huge red flag that your UI is clunky, your API is too slow, or your AI’s suggestions are so bad they’re creating more work, not less.
Monitoring the Platform
You still need to monitor the basics, but they are less important than the effectiveness metrics above.
-
Operational Health: Is the plumbing on? (Latency, Error Rates, CPU). This is the easy stuff. CloudWatch gives it to you for free.
-
Predictions: Is the AI saying weird stuff? Is it suddenly only suggesting code “99213”? A sudden shift in the output distribution is a major red flag.
-
Features (The Input): Is the world changing? Are note lengths suddenly 500% longer? This is how you detect Data Distribution Shifts.
“Concept Drift” is the one that will get you. This is when the meaning of your data changes. The billing authority releases new codes. A note that used to map to “99213” now maps to “99214”. Your model is now fundamentally, dangerously wrong, and it doesn’t even know it.
A Real-World Case Study: The “Concept Drift” Catastrophe A team built a billing code model in 2019. It was great. Then 2020 happened. COVID-19 created a whole new class of billing codes, specifically for “telehealth” and “remote consultation” (e.g., CPT code 99441).
-
The Problem: The model, trained on 2019 data, had never seen these codes. It had no “concept” of a telehealth visit.
-
The Failure: When it saw notes for telehealth visits, it either ignored them or (worse) downgraded them to a “brief nurse check-in” code, which had a much lower reimbursement rate.
-
The Result: The model was “working” (no errors, 99.9% uptime), but it was silently costing the hospital millions in under-billing for six months until an auditor finally caught it. This is Concept Drift, and it’s a silent, costly failure.
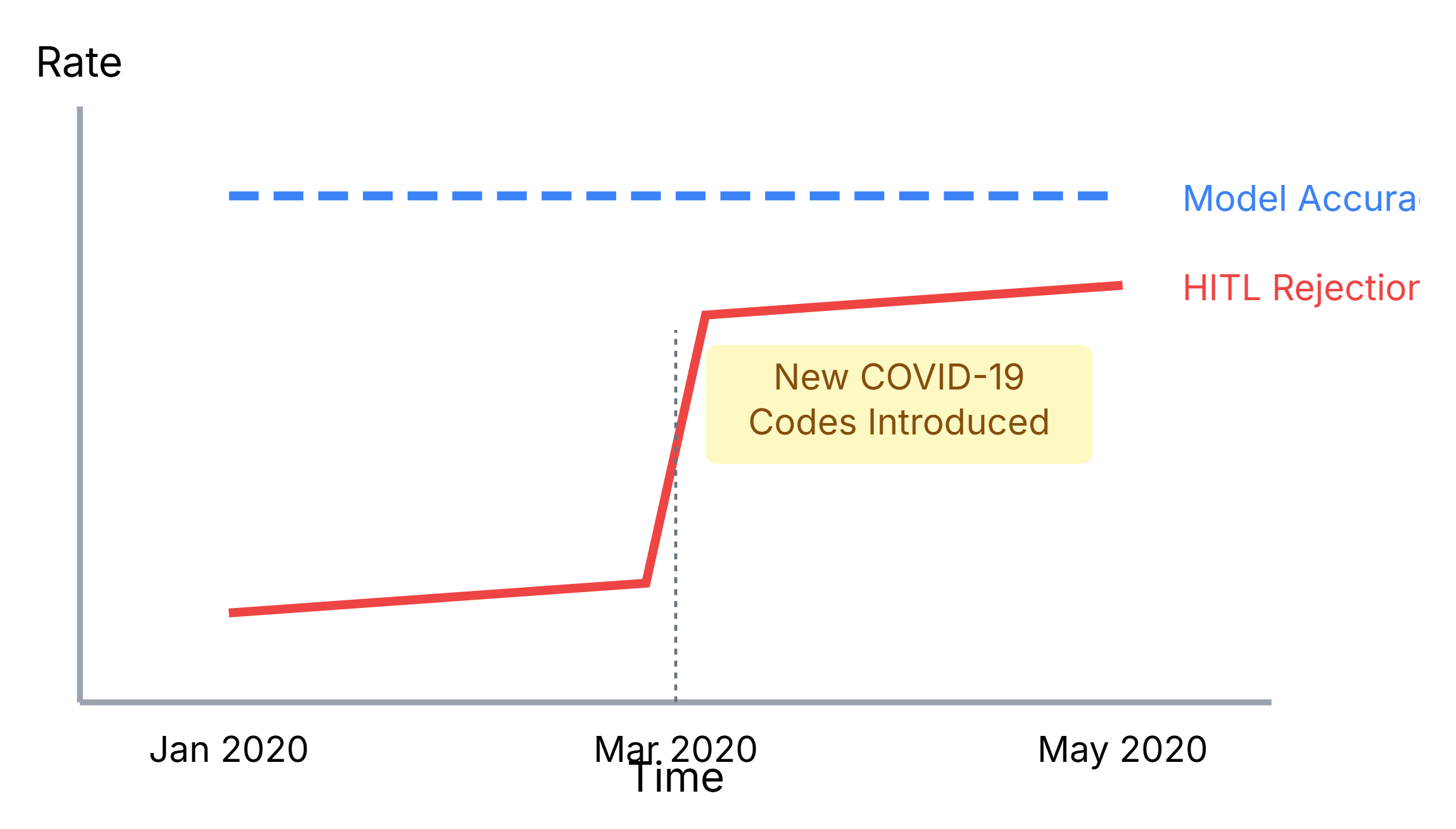
Figure 7: A conceptual graph showing “Concept Drift.” The blue line (Model Accuracy) is high, but the red line (HITL Rejection Rate) suddenly spikes in March 2020 when new COVID-19 codes were introduced.
Feeding the Beast (And Paying For It)
That [Approve] button is your highest-quality, most expensive data-labeling machine. Use it.
Set up a retraining pipeline (e.g., an AWS Step Function triggered by a cron job) that automatically exports approved tasks from RDS to S3 and kicks off a new SageMaker training job.
Now, let’s talk about the bill. The “hype” playbook loves the AWS Free Tier. The real TCO hits you in Month 13.
The “Surprise” Cloud Bill consists of two new taxes:
-
The “Cloud-Native” Tax: This is the over-engineering overhead. NAT Gateways (the classic $2,000/month surprise!), EKS/GKE Control Planes (the $700/month tax just to run K8s).
-
The “AI-Native” Tax: API Fees (to Bedrock) are the most dangerous. An inefficient RAG pipeline can silently cost you thousands.
Our pragmatic stack (Fargate + RDS pg_vector) avoids almost all of a “Cloud-Native” tax. Your only job is to aggressively monitor the “AI-Native” tax.
Justifying the “Boring” Choice (And Keeping Your Team Happy)
You’re going to get pushback, often from your own engineers. You’ll hear “But Kubernetes is what Google uses,” or “This separate vector DB is much faster.”
This is the difference between “Resume-Driven Development” and “On-Call-Driven Development.”
-
Resume-Driven Development is when engineers choose complex, flashy tech because it looks good on their resume. They build it, ship it, and move on, leaving the maintenance nightmare for someone else.
-
On-Call-Driven Development is the mindset that comes from one simple, brutal rule: “You build it, you run it.”

When the same team that builds the feature is also the team that gets paged at 3 AM when it breaks, something magical happens. Their love for “complex microservices” and “bleeding-edge databases” vanishes. They suddenly develop a deep, passionate appreciation for simple, maintainable, and reliable systems.
This is how you protect your architecture. You don’t just enforce a tech stack; you enforce a culture of ownership. The goal isn’t to build the most “impressive” system; it’s to build the system that doesn’t wake you up.
It’s About Trust, Not Magic
The industry is in a race for intelligence. This is a distraction. For high-stakes environments, the primary engineering challenge isn’t intelligence. It’s trust.
A successful AI system in healthcare is not the “smartest” one. It is the most Reliable, Maintainable, and Auditable one.
Start with the real, boring, repetitive problems. Measure success in real-world metrics (“Hours Reclaimed,” not “F1 score”). And build your platform on a foundation of proof, not hype.